УЗКОСПЕЦИАЛИЗИРОВАННЫЕ ПОИСКОВЫЕ ИНТЕРНЕТ-СИСТЕМЫ
Цель проекта: Создание высокорентабельных многоязычных узкоспециализированных поисковых Интернет-систем в форме каталогов, базирующейся на принципах расширенных тезаурусов при построении иерархической структуры каталога.
Базовые принципы предметно-ориентированных поисковых систем:
1. Высокая скорость работы
2. Наглядность представления информации
3. Простота навигации.
За основу иерархического дерева понятий базы данных предметной области берется технология тезаурусов.
ТЕОРИЯ «ИНФОРМАЦИОННОГО ПОИСКА»
Информационный поиск – это процесс отыскания в каком-то множестве документов тех, которые посвящены указанной информационном запросе теме (предмету) или содержат необходимые потребителю факты, сведения.
Дело в том, что сайты и их страницы «разбросаны» в Интернете без всякого порядка и «читать» Интернет подряд – невозможно. Для упорядочивания вывода информации пользователю в поисковых системах используют давно известные способы поиска информации в библиотечном деле по оглавлениям, ссылкам и предметному указателю.
Первый самый естественный способ поиска нужной страницы текста – это оглавление книги. Этому способу поиска в Интернет соответствуют каталоги. В них ссылки на WEB-страницы расположены по рубрикам, перемещаясь по оглавлению каталога, пользователь найдет нужный сайт или страницу.
Второй способ – это ссылки в тексте на важные страницы. В Интернет эту идею превратили автоматическую отправку читателя со страницы на страницу по щелчку кнопкой мыши. Такие ссылки называют гипертекстовыми ссылками.
Третий способ поиска – это поиск по предметному указателю или индексу. Примерно такому, который размещен в технических книгах или научных изданиях. В индексе перечислены важные для книги термины (ключевые слова) и номера страниц, на которых они встречаются. Следовательно, читатель может быстро найти страницу с индексом по ее номеру, указанному радом с индексом.
И если переходы по ссылкам поддерживаются с самого начала появления Интернет и процесс их обслуживания является базовым в сетевой навигации, не требующим создания никакого программного сопровождения. То с поисковыми системами типа оглавления (каталоги) или типа предметного указателя по индексу (поисковые машины) все обстоит иначе.
1. ПОИСКОВЫЕ МАШИНЫ
(search engines)
Сегодня в Интернете доминируют поисковые машины, работа которых основана на принципах предметного указателя (индекса). По сути поисковые машины (или «поисковики») – это главный элемент структуры современного Интернета.
Поисковая машина – это система программ и баз данных, которая составляет и хранит предметный указатель Интернета с индексами (ключевыми словами) и ссылками на WEB-страницы, на которых они обнаружены.
1.1. Как работает поисковая машина
Формирование индекса (предметного указателя ссылок по ключевым словам) состоит из трех этапов:
Этап 1. Сбор адресов WEB- страниц.
Обычно разработчики поисковой машины загружают в нее какой-то начальный список адресов страниц сайтов. Поисковая машина собирает гипертекстовые ссылки с каждой из заданных страниц на другие страницы и добавляет их к первоначальному набору. Таким образом, первоначальный набор адресов страниц быстро увеличивается. Причем «малоизвестные» WEB-страницы, на которые никто не ссылается, имеют мало шансов автоматически попасть в индекс поисковой машины. Выходом из этой ситуации является только ручная регистрация новых WEB-страниц в поисковых системах.
Этап 2. Выкачивание WEB-страниц.
Чтобы вытащить ключевые слова (индекс) со WEB-страниц сайта, необходимо получить находящийся на них текст. Поисковая машина выкачивает гигантский объем текстового материала, хранит его на своих компьютерах.
Этап 3. Индексирование WEB-страниц. Поисковая машина выбирает из выкаченных текстов все ключевые слова и располагает их в алфавитном порядке вместе с номерами страниц, помещая их в «индекс» (предметный указатель). Производится синтаксический и лингвистический разбор слов. В большинстве случаев слова не заносятся в индеек в том виде, в котором они приведены в тексте. Более того, для обеспечения релевантности (соответствия) многословных поисковых запросов в индекс заносится также координата слова на странице. Следовательно, чем ближе координаты ключевых слов из запроса, тем ближе ссылка к началу списка выдаче.
Поисковый индекс представляет собой вывернутую «наизнанку» копию страниц Интернета. Т.е. если в обычном тексте мы идем от страницы к словам, то в индексе поисковая машина идет от слов к страницам. Поэтому индекс поисковой машины называется инвертированным (обращенным или перевернутым). В тоже время копия хранимой WEB-страницы называется прямым индексом. Именно из нее берутся цитаты при выдаче ссылок, и есть возможность показать страницу, которая уже удалена с сайта и является недоступной.
1.2. Выдача пользователю результата поиска
Все подготовительные этапы работы поисковой машины невидимы для пользователя, он видит лишь список ссылок в при выдаче по поисковому запросу. В этом списке, как правило, отражаются:
1. Заголовок страницы (титул).
2. Адрес страницы.
3. Ссылка на сохраненную копию страницы.
4. Цитата из текста страницы с подсвеченным ключевым словом (индексом).
Если в пользовательском запросе было несколько слов, то поисковая машина сравнивает список ссылок на страницы для каждого слова и выбирает только те страницы, номера которых повторяются. Т.е. выбираются только те страницы, на которых одновременно встречаются все слова запроса.
1.3. Алгоритм работы поисковой машины.
Но сайтов очень много, следовательно, необходим определенный алгоритм выбора WEB-страниц для этого списка. Обобщённо алгоритм работы поисковой системы и рейтинг, который она выстраивает на основе пользовательского запроса, учитывает и анализирует следующее:
• Общее количество ключевых слов на сайте.
• Общее количество ключевых слов на странице.
• Соотношение общего числа слов на сайте к количеству ключевых слов на сайте.
• Соотношение общего числа слов на странице к количеству ключевых слов на странице.
• Индекс цитирования.
• Популярность тематики.
• Число запросов по конкретному ключевому слову за определённый период времени.
• Общее количество страниц сайта.
• Применение стиля к страницам сайта.
• Общий объём текста сайта.
• Общий объём сайта.
• Общий объём каждой страницы сайта.
• Общий объём текста каждой страницы сайта.
• Возраст сайта.
• Название URL сайта (имя домена)
• Периодичность обновления информации на сайте.
• Последнее обновление страниц сайта.
• Общее число картинок (рисунков) на сайте.
• Общее количество мультимедийных файлов.
• Наличие замещающих надписей на рисунках (картинках).
• Длину (в количестве символов) замещающих надписей рисунков (картинок).
• Использование фреймов.
• Язык сайта (русский или иностранный).
• Размер шрифта, которым оформлены ключевые слова.
• Жирность шрифта ключевых слов.
• Написаны в разрядку или нет ключевые слова.
• Написаны или нет заглавными буквами ключевые слова.
• Как далеко от начала страницы располагаются ключевые слова.
• Стиль заголовков и наименований ключевых слов.
• Наличие и анализ мета-тэгов.
• Наличие и содержание описания и свойств страницы.
• Наличие файла "робот".
• Географическое месторасположение сайта.
• Комментарии внутри программного кода сайта.
• К какому типу страниц относится каждая страница сайта: html или asp.
• Наличие в составе сайта flash-модулей.
• Наличие в составе сайта страниц с незначительными отличиями друг от друга.
• Соответствие ключевых слов сайта тому разделу каталога поисковой машины, в котором зарегистрирован сайт.
• Наличие "шумовых слов" ("стоп слов").
• Общее количество гиперссылок сайта.
• Количество внутренних гиперссылок сайта.
• Количество внешних гиперссылок сайта.
• Глубина сайта.
• Ряд других специальных технических параметров.
Для того, чтобы сайт мог соответствовать таким критериям была создана очень популярная сегодня технология:
SEO (Search Engines Optimization – оптимизация под поисковую машину) – это поисковая оптимизация страниц сайта с целью получения первых мест в результатах выдачи поисковой машины по клиентским поисковым запросам.
В большинстве случаев поисковое продвижение сайта начинается с утверждения списка ключевых слов или фраз, называемых семантическим ядром сайта. Чаще всего обозначенный список является выдержкой из статистики одной популярной поисковой машины, например: Яндекс (http://wordstat.yandex.ru) и ограничивается несколькими словами, описывающими интересующую тематику. Если учитывать, что Яндекс популярен у 60% русскоязычных пользователей Интернет, то предпочтения более чем 40 % пользователей не берутся в расчёт.
Кроме того, многие поисковые машины алгоритма как такового вообще не имеют. Их работа сводится к очистке текста сайта от программного кода и выстраивания слов, встречающихся на сайте по их частоте.
Чем сложнее алгоритм работы поисковой машины, тем, с одной стороны, больше вероятность получения наиболее точных и полных результатов, но, с другой стороны, больше вероятность ошибок в работке самого алгоритма. Усложняя алгоритм работы поисковой машины можно как достичь более полных и точных результатов, так и, наоборот, получить менее точные и полные результаты.
Любой инженер знает, что чем сложнее какая-либо машина, тем, с одной стороны, она может выполнять больше функций, но, с другой стороны, больше вероятность выхода её из строя.
Пять "постулатов" работы поисковой системы:
1. Даже в самых "умных и точных" поисковых системах сайты проходят "ручную" проверку (визуальный просмотр) администратором поисковой системы (модератором).
2. Поисковые системы стараются держать в секрете точную формулу (алгоритм) своей работы, на основе которой строятся их рейтинги. Этим достигаются две основные цели: защита от конкурентов и защита от направленного поискового спама.
3. Любой алгоритм разрабатывается людьми. Людям свойственно ошибаться. Рейтинг поисковой системы может также содержать ошибки.
4. Алгоритм работы поисковой системы "умнеет" вместе с самими разработчиками, его создавшими. Чем больше знаний у самих разработчиков, тем "умнее и точнее" работа поисковой системы, тем удобнее искать и получать в ней необходимую информацию.
5. Поисковые системы - не благотворительные организации. Основной целью работы поисковой системы является получение прибыли. Любой рейтинг можно купить. Чем сложнее это сделать, тем честнее поисковая система и рейтинг сайтов, которые она выстраивает.
1.4. Статистика от поисковых машин
Немного статистики от самой популярно в русском Интернете поисковой машины - Яндекс (http://www.4p.ru/main/research/132961/print_article/)
1. Пользователи русскоязычного интернета просматривают страницы результатов поиска всех поисковых машин более 1,9 миллиарда раз в месяц.
2. К поисковым системам Рунета пользователи ежедневно задают около 48 миллионов запросов в день (при ежедневном просмотре страниц результатов поиска более 63 миллионов раз).
3. За поиском нужного ответа средний пользователь проводит меньше 5 минут. Когда среднему пользователю нужно что-то найти — он обращается к поиску один или два раза и делает в среднем пять запросов.
Сравнительный анализ работы поисковых машин можно найти по ссылке: http://analyzethis.ru
2. КАТАЛОГИ
(directories)
Всем с давних времен известно, что залогом успеха, как правило, является следование принципу:
«ВСЕ ГЕНИАЛЬНОЕ – ПРОСТО»
Простейшая поисковая система как раз и представляет собой КАТАЛОГ, ОРГАНИЗОВАННЫЙ ПО АЛФАВИТУ. .
2.1. Почему сегодня каталоги проигрывают индексным поисковым машинам?
Главный недостаток существующих каталогов WEB-каталогов в том, что они копируют интерфейс поисковых машин. А ведь каталог должен иметь свой присущий только ему навигационный стиль или особый вид пользовательского интерфейса.
2.2. Преимущества каталога перед поисковой машиной
Во-первых. Дополнительная навигация. В поисковой машине за универсальность поиска приходится платить определенностью ссылок. У ссылки найденной по индексу просто не может быть уникального сортировочного атрибута, т.е. того, что позволит упорядочить ссылки по алфавиту. Поэтому в интерфейсе поисковых машин все ссылки снабжаются порядковым номером, чтобы как-то ориентировать клиента в поисковой выдаче.
Другое дело специализированный каталог, например каталог коммерческих предприятий или информационных сообщений (новостей). У каждого из них должен (просто обязан) быть сортировочный атрибут. У каталога ссылок на сайты коммерческих образований – это название предприятий. А у новостных сообщений – дата публикации новости.
| Наименование ссылки | Элемент сортировки …<a href> | Адресная строка href=”…” | Содержание текста ссылки <a ..>”…”</a> | Подсказка title=”…” |
|---|---|---|---|---|
| Дескрипторы | URL-адрес каталога | Имя дескриптора | Список дескрипторов и ключевых слов | |
| Ссылка на сайт коммерческого образования | Название компании, фирмы, организации | URL WEB-страницы | Фраза на WEB-странице с ключевой фразой из запроса клиента | Текст из мега-тега «Description» сайта коммерческого предприятия |
| Новостная ссылка | Дата появления новости | URL WEB-страницы | Заголовок новостного сообщения | Аннотация новостного сообщения (если таковое имеется) |
По таким атрибутам и организуется дополнительная навигация в каталоге. Такую навигацию поисковая машина себе позволить не может. Причем, речь идет о навигации, которая выполняется в уже сгенерированной странице, т.е. на стороне клиента – в окне браузера (например, средствами JavaScript), исключив тем самым лишнее обращение к серверу.
В до Интернетовскую эпоху в поисковых системах использовался механизм отсылки клиента от ключевых слов к дескрипторам. Аналогично следует поступить и в новых поисковых Интернет-системах.
Только делать это необходимо не принудительно, предоставив пользователю самому принять решение о навигации в иерархии тезауруса.
Для этого на экране необходимо вместе с дескриптором показать все ключевые слова, соответствующие выбранному объекту поиска, с выделением дескрипторов на экране (например, жирных шрифт).
Во-вторых. Увеличенный объем списка ссылок.
Как уже было замечено, при наличии сортировочного атрибута у ссылки можно организовать быструю навигацию в каталожном списке. Следовательно, нет особых ограничений на его длину списка. А ведь список, выдаваемый поисковой машиной ограничен, как правило, десятью элементами. Некоторые поисковые машины позволяют настроить интерфейс до 50..100 элементов в списке, но для этого следует произвести установки в поисковике. Но такое желание возникает у весьма ограниченного числа пользователей. А посмотреть следующую десятку поиска привлекает также не всех желающих.
По статистике из 100 человек, просматривающих первую страницу с результатами поиска, на вторую переходят чуть меньше половины. Дальше третьей зайдут лишь пятеро. Таким образом, с вероятностью 95% люди остановятся на первых 30 ссылках, показанных поисковой системой.
Поэтому результат работы поисковой машины на запрос пользователя – это даже не иголка в огромном стоге сена. Это песчинка на морском пляже.
В-третьих. Богатейший опыт человечества в составлении каталогов.
Студенческо-аспиранский подход присущий современным поисковым машинам должен уступить место научно-мотивированному академической, но удобной в использовании стратегии тематических каталогов. Никакой индекс цитирования не может подменить грамотно составленной классификационной иерархии понятий, составленной с использованием многовековых исследований человечества в области представления знаний и искусственного интеллекта. Судите сами.
Немного истории
Известно утверждение: "Знание – сила". Тогда информация, питающая знание – источник этой силы. Всем, что имеет человек сейчас, он обязан своему умению воспринимать и обрабатывать информацию. Вся история развития человеческого общества сопровождалась совершенствованием этого умения и ростом объема информации. Причем объем информации увеличивается вдвое быстрее промышленного потенциала. Основная проблема связана с возможностями человека обрабатывать растущие информационные потоки.
В до Интернетовском периоде все информационно-поисковые системы классифицировали на две группы:
• Документальные (поиск документов).
• Фактографические (поиск фактов, характеристик, данных и т.п.)
Любой поиск ориентируется на сокращенное название или аннотацию объекта поиска, позволяющее судить об искомом объекте как о предмете поиска.
Причем предпочтение всегда отдавалось структурам дескрипторного типа.
Дескрипторы – это термины естественного языка, выражающего определенные понятия. Словарь дескрипторов с указанием между ними смысловыми отношениями, охватывающими определенную предметную область, называют информационно-поисковым тезаурусом.
Тезаурус (от греч. — сокровище) в современной лингвистике — особая разновидность словарей общей или специальной лексики, в которых указаны семантические отношения (синонимы, антонимы, паронимы, гипонимы, гиперонимы и т. п.) между лексическими единицами. Таким образом, тезаурусы, особенно в электронном формате, являются одним из действенных инструментов для описания отдельных предметных областей.
В отличие от толкового словаря, тезаурус позволяет выявить смысл не только с помощью определения, но и посредством соотнесения слова с другими понятиями и их группами, благодаря чему может использоваться в системах искусственного интеллекта.
Тезаурус – полный систематизированный набор терминов в какой-либо предметной области.
Тезаурус — особая разновидность словарей общей или специальной лексики, в которых указаны семантические отношения (синонимы, антонимы, омонимы, гипонимы, гиперонимы и т. п.) между лексическими единицами. Таким образом, тезаурусы, особенно в электронном формате, являются одним из действенных инструментов для описания отдельных предметных областей.
В отличие от толкового словаря, тезаурус позволяет выявить смысл не только с помощью определения, но и посредством соотнесения слова с другими понятиями и их группами, благодаря чему может использоваться в системах искусственного интеллекта.
Дескрипторы дополнялись ключевыми словами. Доле в том, что набор ключевых слов, часто используемых клиентом при поиске должен дополнять систему дескрипторов информационно-поискового тезауруса. Дело в том, что многие пользователи поисковых систем не имеют достаточного образования и просто не знают специфичных терминов, применяющихся для точного позиционирования на объекты предметной области. Использование же общепринятых (обиходных, употребляемых в разговоре) терминов позволяет сделать систему понятной и общедоступной. Кроме того, это позволяет расширить его словарный запас, демонстрируя наряду с разговорными фразами научные (специфические) термины и названия.
При навигации в каталоге старых системах поиска каждое ключевое слово заменялось близким ему по смыслу дескриптором информационно-поискового тезауруса, по сути, являясь его синонимом.
Синонимы — слова одной части речи, различные по звучанию и написанию, но имеющие одинаковое или очень близкое лексическое значение, например: кавалерия — конница, смелый — храбрый. Синонимы служат для повышения выразительности речи, их использование позволяет избегать однообразия речи. Следует различать синонимы и номинальные определения — последние представляют полную тождественность.
Но, казалось бы, применение синонимов – должно приводить к потерям информации при поиске, т.к. неоднозначность не позволит зафиксировать отношения между терминами. Вот тут и начинает работать принцип обучения. Связи и переходы в ветвях тезауруса выстраиваются строго по специализированным (строго научным терминам) и только. Прочие ключевые слова только дополняют тезаурус. Другими словами – лексику тезауруса составляют не только дескрипторы, но и их синонимы, которые не являются дескрипторами.
Поэтому, хочешь перемещаться в тезаурусе – осваивай специфичные термины. В этом обучающая составляющая такого каталога (поисковой системы). В этом и есть главное различие дескрипторов и ключевых слов (синонимов).
Первые информационно-поисковые тезаурусы были разработаны в 60-70-е годы:
- тезаурус Агенства службы технической информации США (1962 г.):
- тезаурус технических и научных терминов Министерства обороны США и Объединенного совета инженеров (1967 г.) – 23364 слова, из которых 17810 слов выступают в качестве дескрипторов);
- тезаурус научно-технических терминов под общей редакцией Ю.И. Шемакина (М., Воениздат, 1972 г.);
- тезаурус международных информационных служб по атомной энергии (1966 г.);
- тезаурус Международного агентства по атомной энергии в Вене (6-е издание вышло в 1974 г.);
- отраслевой тезаурус: словарь дескрипторов по химии и химической промышленности (НИИТЭХИМ, 1973 г.) – 5373 ключевых слова, из которых 1033 дескриптора;
- тезаурус дескрипторов по образованию Информационного центра народного образования США (1967 г.).
До недавнего времени считалось, что совершенствование поисковых систем во многом зависят от достижений в области семантической информации и направлений лингвистики. Это послужило толчком к интенсивным исследованиям в области этих наук. Главными направлениями здесь выделялись:
1. Реферирование документов. Одной из задач даже рассматривалась технология автоматизированного реферирования документов, т.е. выделения в тексте таких предложений, которые содержат наиболее значимые для данной области знаний термины. Из этих предложений и должен был формироваться реферат документа. Поисковые системы Интернета сегодня отказались от этой идеи. В Google и Яndex работают не ученые-исследователи, а профессиональные программисты, которые мало заинтересованы в осуществлении фундаментальных исследований поисковых механизмов.
2. Синтез предложений. Другой путь состоял из синтеза реферативных предложений из выделенных в тексте наиболее значимых терминов. Здесь преследовалась цель максимально улучшить «взаимопонимание» между человеком и компьютерами.
Ни одна из современных поисковых машин не способна на такое.
В-четвертых. Решение проблемы неопределенности или SEO-прессинга.
Многие запросы невозможно понять однозначно. Например: «дизайн», «автомобили», «спорт» и др. Такие запросы называются информационными. Лучшим ответом на них является подборка, в которой пользователям предлагаются ссылки на ресурсы по различным смысловым направлениям запроса.
Так, в выдаче в ответ на запрос «дизайн» должны быть ссылки на сайты о веб-дизайне, ландшафтном дизайне, дизайне интерьера и др. Сформировать качественную политематическую подборку ссылок непросто. Особенно в условиях, когда оптимизаторы рассматривают популярные информационные запросы как цели для продвижения сайтов своих клиентов. В результате такого SEO-"прессинга" наверх пробиваются только ресурсы, продвижение которых наиболее окупается, и выдача становится однообразной, состоящей из ссылок на сайты с однотипными коммерческими предложениями.
На самом деле проблема заключается в самих запросах, которые состоят из одного, двух или трех слов (т.е. являются малословными). А слова таких запросов являются омонимами. Омонимы — разные по значению, но одинаковые по написанию и звучанию единицы языка (слова, морфемы и др.).
По статистике Средняя длина поискового запроса сегодня — 2,5 слова. В 1997 году средний запрос состоял всего из 1,2 слова. Т.е. пользователи стали многословнее. Это объясняется тем, количество информации в Интернете во много раз увеличилось, и для того чтобы найти ответ на свой вопрос, бывает нужно сформулировать запрос точнее.
| Длина поискового запроса (слов) | Доля запроса, % | |||
|---|---|---|---|---|
| Рунет | Яндекс | Рамблер | ||
| 2 | 25,56 | 28,076 | 27,784 | 30,526 |
| 3 | 23,18 | 24,261 | 24,226 | 22,683 |
| 1 | 13,17 | 16,999 | 17,17 | 21,075 |
| 4 | 14,89 | 14,966 | 15,123 | 13,285 |
| 5 | 7,88 | 7,82 | 8,054 | 6,592 |
| Другие | 7,66 | 7,895 | 7,652 | 5,843 |
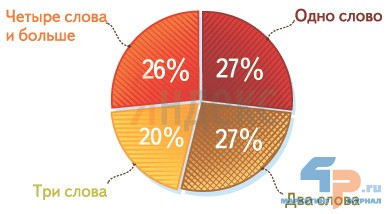
Эту проблему можно решить только одним методом – предоставить пользователю дополнительный выбор из омонимов, относящихся к разным категориям или предметных областей человеческого знания. Такой выбор можно реализовать в каталоге, обозначив иерархические ветки перемещений по достижении этого понятия в тезаурусе, опускаясь по дескрипторам, которые поочередно играют роль гиперонимов и гипонимов.
Гипероним — слово с более широким значением, выражающее общее, родовое понятие, название класса (множества) предметов (свойств, признаков). Гипероним является результатом логической операции обобщения или в математическом смысле — дополнения до множества. В лингвистике, гипероним — понятие, в отношении к другому понятию выражающее более общую сущность.
В отношении некоторого множества объектов гиперонимом является понятие, отражающее надмножество к исходному.
Гипоним — слово с более узким значением, называющее предмет (свойство, признак) как элемент класса (множества).
Можно только догадываться как изменит Интернет такая навигация для будущих поколений его пользователей. Ясно одно, что нас ждет серьезная модификация Интернет-интерфейсов.
В-пятых. Идеальное место для размещения контекстной рекламы.
По данным статистики приблизительно в каждом десятом поисковом запросе присутствует название организации или сайта. Для общения с поисковой машиной чаще всего используют существительные — эту часть речи содержат 75% запросов к «большому» поиску и 96% запросов к поиску по картинкам.
А теперь посудите сами, какой сайт может сравниться с каталогом, где одновременно присутствуют все слова соответствующие терминам конкретной предметной области (см. определение тезауруса).
Главные заказчики контекстной рекламы — это представители бизнесов с высокой стоимостью привлечения клиента: производители и поставщики промышленных товаров (B2B-сегмент), участники строительных, автомобильных, страховых и финансовых рынков. Кроме того, значительную долю оборота рынка обеспечивают продавцы бытовой техники, представители сектора деловых услуг, туристического сектора и сектора недвижимости.
В2В – сокращение от английских слов «business to business», в буквальном переводе – бизнес для бизнеса. Это сектор рынка, который работает не на конечного, рядового потребителя, а на такие же компании, то есть на другой бизнес.